Automated Offside VAR Detection in Soccer
Topics: Computer Vision, Deep Learning, Image Processing, Pose Estimation
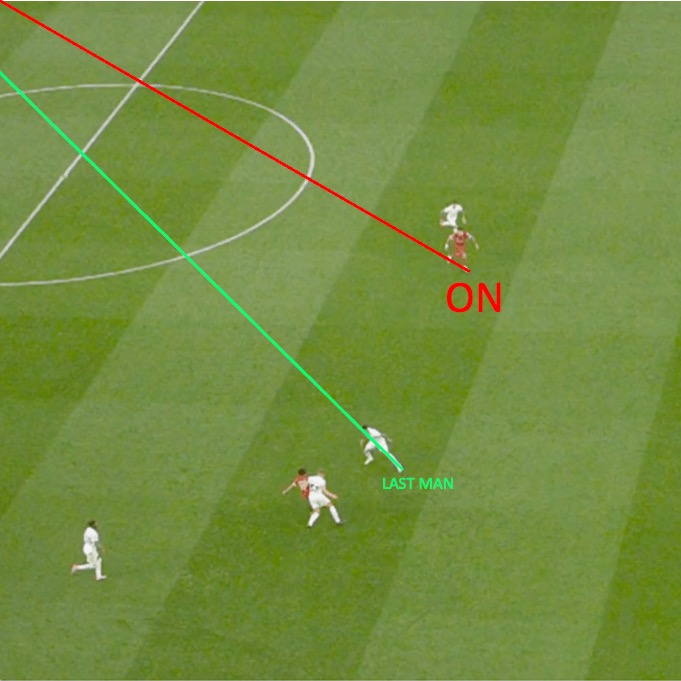
- Offside decisions in soccer can make or break a team's chances of securing a goal nowadays. To make matters worse, current video assistant referee (VAR) technology is super inconsistent due to human error and a lack of automated final decision outputs. I sought to predict players positioned offside given a specific snapshot of a soccer match.
- CV pipeline: determined the relative positions of the players on the field by using a vanishing point detection algorithm and accurately localizing the players. Deep learning-based pose estimation was used to detect the individual body parts of the player. I used a greedy algorithm for 2D pose association and used those 2D association poses to generate and track the actual 3D skeletons of the players. Next, I used k-means clustering for team classification. This wasn't as effective on its own, so I incorporated the DBSCAN algorithm in my clustering model to identify noisy data points and remove them. Finally, I ran an offside detection algorithm to make a final offside decision call on the snapshot.
- Offside detection algorithm: the final defender is identified on the field, and they are marked as the offside line position that other attacking players shouldn't cross. When the passer makes the pass to an offside candidate, they are identified as offside or not depending on their position relative to the second-last defending player.
- Results: an offside decision call accuracy score of 87.4%.
- Separate from this programming section, I also wrote an article analyzing the effects of current VAR and the future of this technology. You can read the article and view the relevant citations/references for the entire project.
PSS Innovation for a Capstone Client
Topics: Service Design, UX Design, Ideation, Market Research
- Analyzed the product-service system (PSS) of a therapy practice based in Pittsburgh, PA. Conducted user experience research to identify where a new service may satisfy unmet consumer needs.
- Using key service design methods (service blueprints, personas, value flows, etc.), we sought to understand the relationship between the clinicians and actors present in the front-stage and back-stage of the therapy practice.
- We redefined value exchanges between actors in the PSS and explored an opportunity that had high leverage for scalability: innovating the teaching procedure for clinicians seeking how to build their own therapy practice.
- Our ideation process involved research method planning, generating innovation concepts, and focusing on a particular hypothesis. Through iteration, feedback, and refinement loops, we addressed many of the pain points and concerns the business faced in its teaching methodologies and matched the expected cost and investment budgeted.
Churn Prediction w/ Human Emotion Forecasting
Topics: Full Stack Development, Machine Learning, Exploratory Data Analysis
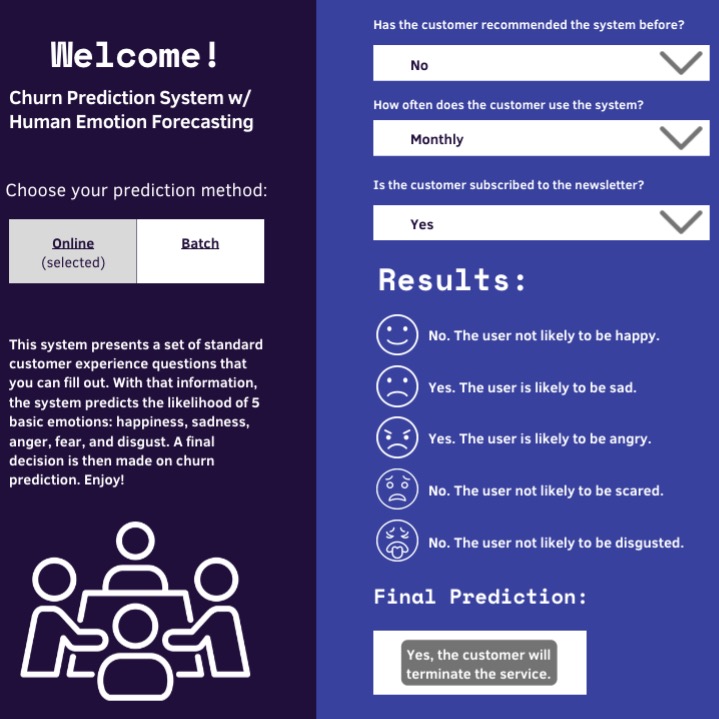
- Implementation of a customer churn prediction system focusing on human emotion - a vital factor that affects customers when purchasing goods and services. Most churn predictions don't factor in human emotion, so I sought a way to measure emotion to enhance the accuracy of customer churn predictions.
- Based on existing dataset categories stored in an SQLite database, I modeled the system to consider 5 basic emotions: happiness, sadness, anger, fear, and disgust. After testing through performance validations of various supervised learning algorithms, I stuck with a logistic regression model that outputs a final churn prediction decision after presenting whether the user is likely to be feeling a particular emotion or not.
- Finally, I deployed the system as a web application using a Django backend with API endpoints on Heroku. The React front-end gets data by making API calls to the SQLite database. The system can operate in real-time via online-input prediction or batch prediction.
- Results: a +12.3% churn prediction accuracy score compared to a regular churn prediction system that doesn't factor in emotion.
Analog Synth Oscillator w/ 8-Step Sequencer
Topics: Electronics, Circuit Design, DIY, Soldering, Arduino, Sequencers
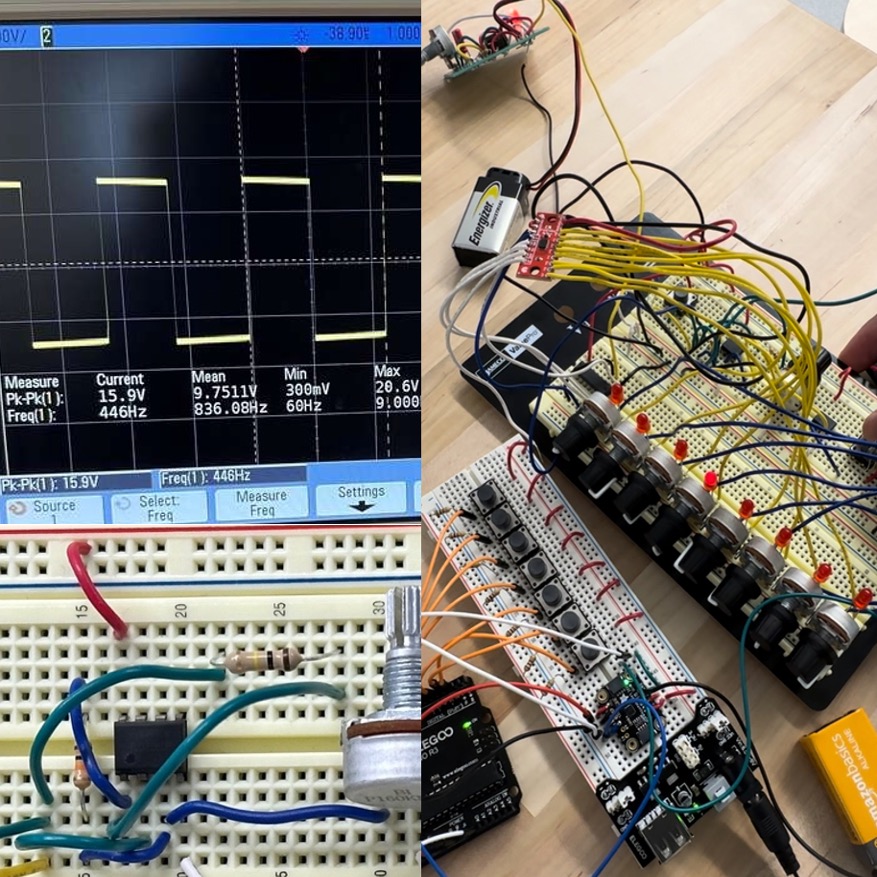
- My first experience with electronics! I built an op-amp Schmitt trigger oscillator for generating audio, exploiting hysteresis to create sustained oscillations with a square wave output. I incorporated an op-amp integrator into the design to amplify the audio signal, utilizing a feedback loop to stabilize the circuit.
- Improved the amplitude of the oscillation by switching from a dual-sided (0V to +5V) to a single-sided voltage supply (-9V to +9V), enabling a higher peak amplitude and resulting in a louder sound output.
- The oscillator is connected to buttons and programmed via an Arduino microcontroller using a DS1841 I2C logarithmic potentiometer to play a 7-note scale. The logarithmic frequency scaling is used for more of a natural pitch control.
- The design also incorporated an 8-step sequencer using a 12-stage binary counter, a clock pulse generator using a 555 timer on a soldered circuit board, an 8-channel multiplexer breakout, and 8 rotary potentiometers to craft dynamic sound patches. Here's a short clip of a simple sample patch I created!

SCAN: The Steel City Analysis Network
Topics: Data Collection, Exploratory Data Analysis, Macroeconomic Analysis
- Founded SCAN with business and economics undergraduates to provide a professional analysis of contemporary economic issues specific to the Pittsburgh region.
- Compiled extensive Python and R scripts involving data collection, filtering, and modeling from data from the US Federal Reserve, US IPUMS, and the FRED database. From here, I analyzed the change in daily job postings, the shift in prevalent industries, and the structural transformation of Pittsburgh over time using principle macroeconomic concepts.
- Results: iron mills, steel mills, and steel product manufacturing have seen the biggest decline in labor force population out of the investigated steel and manufacturing-related industries. In addition, following the deindustrialization of the U.S. in the late 20th century, there was a noticeable shift in the occupational job position composition within Pittsburgh's steel and manufacturing sector that can be attributed to a decrease in the demand for blue-collar positions within the industry.

OER: Special FX (First-Year Experience) CMU-Q Library
Topics: User Research, Resource Development, Academic Writing
- Collaborated on the production of an open educational resource (OER) for first-year CMU-Q students covering academic research and library skills using Springshare LibGuides.
- Ran user evaluation studies where our primary goals involved measuring student reading habits and overall library familiarity. I focused on how first-years can improve their active reading skills at the college level.
- Utilized the content management and curation platform which required the use of heavy research, writing, editing, teamwork, & digital literacy skills.
- Our findings and content influenced CMU-Q's C@CM material, driving improvements in library engagement.

Rubik's Cube Solver
Topics: Python, Object-Oriented Programming, Algorithm Design
- My first coding project - built using Python! This solver was created using top-down code design and is over 1000 lines of code. This was an interesting problem since solving a Rubik's Cube via brute force isn't computationally viable!
- Rubik's Cube representation was implemented using an assigned Cube class with rotation matrix logic. A dedicated GUI and help guide present. Animations use the model-view-controller (MVC) paradigm.
- Computation speed was sufficient, but solutions were over 200 moves long on average. I used a simple optimizer to reduce the average number of moves by 38%.
- Revisited this project a month later in an attempt to use Thistlethwaite's algorithm and a 4-group Cube representation; got the IDA* search down but the lack of pruning tables made the solving time slower.